背景
现代化的前端项目中很多都使用了客户端渲染(Client-side Rendering, CSR)的单页面应用(Single Page Application, SPA)。在大多数情况下,它们都应该通过加载 JavaScript 脚本在浏览器中执行以将页面的大部分视图渲染出来,以及获取页面所需要的数据。单页面应用有着许多非常显著的优势,如它们(单页面应用)依赖的公共资源通常仅需加载一次。数据都是通过异步的 JavaScript 与 XML 技术(Asynchoronous JavaScript and XML, Ajax)加载的,异步性能往往非常高。在路由切换时,仅需刷新和(或)更改页面的一部分,而不需要重新加载整个页面以达到切换路由的目的,因此路由的切换在单页面应用中显得比较流畅自然。然而,单页面应用也存在着很多缺陷,它们包括但不限于:
- 搜索引擎无法收录我们的网页,因为绝大部分的视图和数据都是通过 JavaScript 在浏览器中异步渲染或加载出来的。即使现在有一些搜索引擎爬虫(如 Google)已经具备了爬取单页面应用的能力(即爬虫具备了解析这些 JavaScript 代码的能力),但等到所有搜索引擎爬虫都支持爬取单页面应用显然不是一个好想法;
- 对于业务逻辑复杂一些的单页面应用,它们用于渲染页面的 JavaScript 脚本(可以称为 Bundle)通常体积巨大。试想加载一个上百 KB,甚至几 MB 的 JavaScript 脚本,特别是在没有内容分发网络(Content Delivery Network, CDN)的情况下,首页渲染的时延是非常大的。
同构与服务端渲染
对于单页面应用上述的缺点,我们可以考虑利用 Webpack 的多入口配置,将原有的单页面应用同构成与原先的前端路由相似甚至相同的目录结构,指定打包后输出的 HTML 模板。在 Webpack 对整个应用打包之后,将根据入口配置从指定的 HTML 模板生成对应的 HTML 文件,交给位于前端页面与后端之间的中间层(通常使用 Node.js 编写,作为服务端渲染(Server-side Rendering, SSR)的服务器)。注意,此时 Webpack 生成的这些 HTML 文件并不能完全被浏览器解析,因为这些文件里还有提供给中间层渲染使用的一些插值,在用户访问中间层路由时,这些 HTML 文件将被用作服务端渲染的模板,将中间层从后端 API 获取的数据按照插值的格式填充(也可以称为“渲染”),最后发送给用户。
进一步理解
到目前为止,这个描述还是十分令人困惑。不过我们没有必要一直纠结这些问题,因为下面的图片也许可以帮助我们进一步了解整个流程:
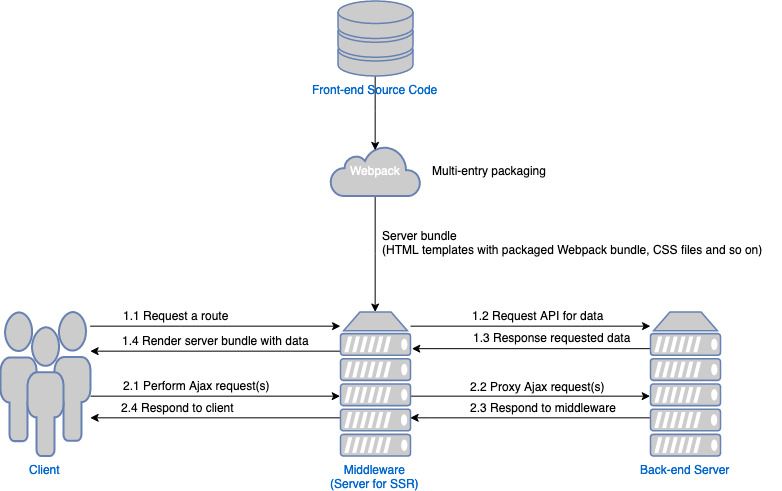
有了上图的帮助,我们可以将整个流程归纳为:首先,和单页面应用一样,前端代码先要经过 Webpack 的打包编译,产物也和单页面应用一样,也是 HTML、JavaScript、CSS 文件。唯独与单页面应用不同的是,此时的 HTML 文件还存在着插值,这些是要给中间层插入数据最后渲染给用户的;其次,用户开始请求一个路由(图中 1.1),他们现在请求的路由并非前端的路由而是中间件路由(所谓的“中间层”其实可以理解为一个 Node.js 服务器),如果请求的路由与中间件中定义的路由相匹配,中间件就会根据路逻辑向后端服务器获取指定的数据(图中 1.2),后端返回相应的数据(图中 1.3),经过一定的处理后将数据插入到指定的 HTML 文件中(这些 HTML 文件是从 Webpack 打包生成的);然后中间层将渲染出的最终 HTML 发送给客户端(图中 1.4)。客户端收到响应后,接下来的流程就和单页面应用一样了:浏览器解析中间层发来的 HTML 文件,执行里面的 Bundle。也许 Bundle 中包含了 Ajax 请求,因此浏览器向中间件发送了 Ajax 请求(图中 2.1)。但是中间件并不直接提供后端 API 服务,因此,它必须提供一个可以将请求转发至后端 API 的代理(图中 2.2)。后端将数据返回给中间层(图中 2.3),中间层的代理又将数据发送给客户端。因此,这种情况下的 Ajax 请求,不论是对于客户端还是后端,都是透明的,即它们在使用 Ajax 进行数据传送时,对中间层的存在都毫不知情。
将整个流程用一句话描述,即:客户端访问了中间层路由,中间层返回渲染好一部分数据的带 Bundle 的 HTML 文件,再由浏览器执行 Bundle 以加载完剩下的数据。
基于上面的所有描述,我们大致清楚了中间层应该至少扮演两种角色:
- 根据客户端请求获取相应的数据并响应渲染好的 HTML 文件
- 代理客户端和后端之间的 Ajax 请求
- 充当静态文件服务器(这并不是必须的,因为可以将静态的图片、JavaScript 代码、CSS 文件等上传至 CDN)
最佳实践
至此,我们已经对整个过程有了充分的认识。接下来,我们可以讨论一些实际性的配置,例如:我们应该如何对 Webpack 进行配置,如何编写一个中间层等等。
为了更方便地了解自己的水平是否适合继续了解和掌握下面的内容,以下列出了下文中使用到的技术:
- Node.js
- TypeScript
- React.js
- Webpack
- Koa.js
关于我们为何使用 TypeScript 构建我们的实践项目,请参阅 5 Key Benefits of Angular and TypeScript
如何实践
需求分析
我们可以从 GitHub API 中获取 GitHub 上指定用户的 Gists,根据返回的数据进行渲染。如果时间允许的话,我们也许还能将所有的 Gist 进行分页渲染。
在这之前……
笔者在实际项目中使用这个方案开发时,遇到了诸多问题。幸运的是,笔者已经基本排除了绝大部分可控的错误并且提供了一份最基础的模板。在接下来的探索中,我们将使用这套模板编写一个小 Demo:从 GitHub Public API 中获取一些数据,并按照一定的逻辑进行访问的渲染。不过,笔者仍希望介绍一下这套模板中的配置,以及为什么需要这样进行配置。因为笔者坚信:授人以鱼,不如授人以渔。
查看这套模板的 GitHub 仓库
请注意,笔者并不打算直接将这套模板作为实例继续开发,因此,一个新的仓库是十分必要的。
笔者将会在 lenconda/webpack-ssr-practice 中同步这篇文章的所有更改。在每一段结束后,如果有必要的话,笔者也会提供对应时间点的 Commit ID,以便于我们对整个过程有更深刻的印象。
Webpack 配置
通常,各种前端框架的脚手架都有自己的 Webpack 配置,以便于开发者快速进入开发状态。然而,在本文中,我们可能无法找到满足我们需求的配置方案。因此,为了达到我们预期的结果,我们应该从零开始配置 Webpack。
若你希望在这之前对 Webpack 有更深入的了解,请移步 Webpack 的官方文档。
前置知识
在 Webpack 中,指定入口文件应该在 entry 字段中以键值对的形式声明。其中,键为入口的名称,值为该入口所在的文件的路径,路径可以是相对路径,也可以是绝对路径。在本文中,如果没有特殊声明,路径一律采用绝对路径的形式。
在打包时,Webpack 会读取每个 entry,经过相对应的 loaders,根据 output 字段的配置生成输出文件(有时也称为“出口文件”)。例如,有如下一段配置:
1 | module.exports = { |
Webpack 将会输出一个类似于 ../dist/static/js/root.ae5fb09e.js 的出口文件。其中,[name] 是 entry 字段中每个键的占位符,[hash] 是文件哈希值的占位符,[hash:8] 指的是取文件哈希值的前 8 位。
对 Webpack 生成的文件哈希值感兴趣,或者想进一步了解为什么打包出的文件需要将哈希值插入文件名中,请移步 Webpack 的官方文档
对特定的目录扫描生成多入口配置
由于我们采用了多入口方案,并且将每个页面作为一个入口,因此我们无法估量一个项目究竟有多少个页面(即我们无法估量一个项目有多少个入口)。因此,我们应该编写一个方法,按照一个特定的模式匹配指定路径下的入口文件,递归生成一个入口列表。我们可以编写如下的方法:
1 | function getEntries(searchPath, root) { |
接下来,我们编写以下代码:
test.js
1 | console.log(getEntries( |
这段代码被期望可以从当前路径父级目录的 pages 目录下找到所有包含 index.tsx 文件的目录。我们在项目根目录中运行这段代码,可以得到如下的结果:
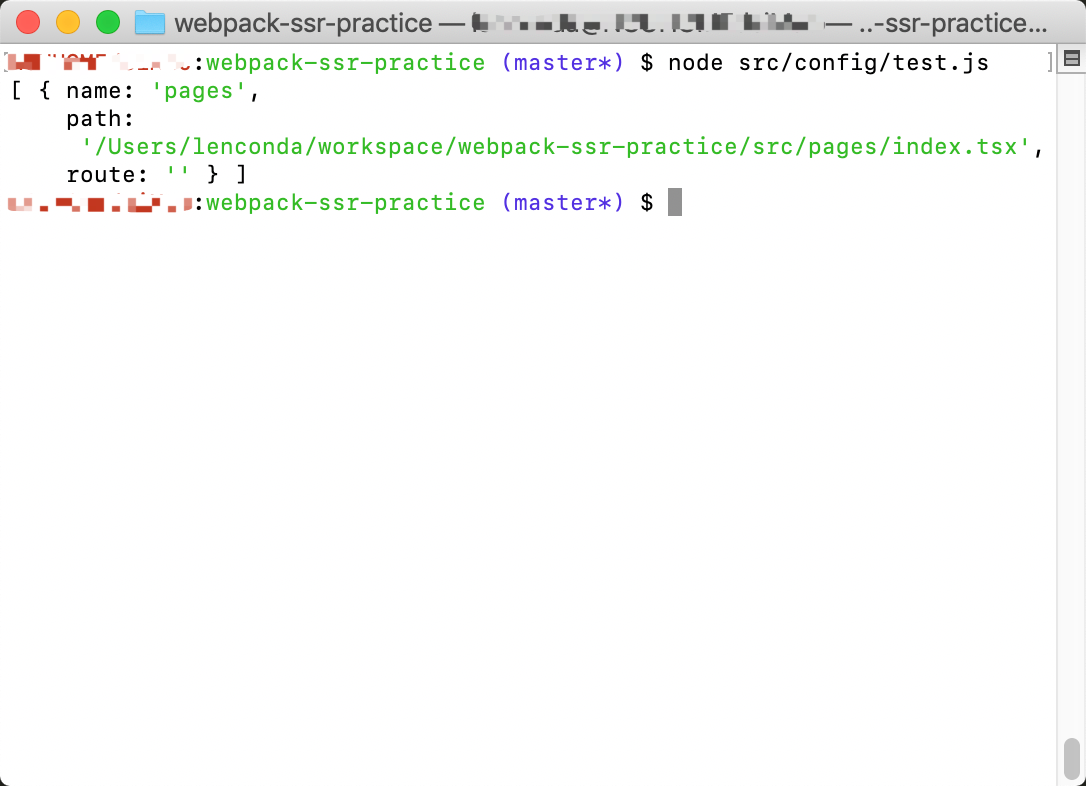
其中,name 指定了入口的名称,path 指定了入口文件的路径,route 指定了入口文件的路由名称(这个字段将在生成出口文件名以及生成 HTML 模板中发挥作用)。
生成对应的服务端渲染模板(Server Bundle)
入口和出口
现在,我们可以得到入口文件列表了:
1 | const entries = getEntries( |
因此,entry 和 output 可以是这样的:
1 | entry: { |
以上这段代码中,我们也许可以发现很多难以理解的配置项。不过我们不必担心它们,只需理解我们是如何用 getEntries() 的输出来配置入口和出口的。其中的一些技术细节(如 ...,Object.assign() 等),因篇幅所限,在这里不做详细阐述。
若你希望继续深入理解这些操作符或方法,请移步:
Object.assign() - MDN - Mozilla
展开语法- JavaScript | MDN
输出 HTML 模板
HtmlWebpackPlugin
我们使用 HtmlWebpackPlugin 的 Webpack 插件将多入口输出至对应的 HTML 中。值得注意的是,我们所需要的 HTML 模板可能不止一个,因为不同的页面可能有不同的搜索引擎优化(Search Engine Optimization, SEO)配置。因此,我们需要将公共部分(如 footer、共用的head等)提取到一个独立的 HTML 文件中,再在每个 HTML 模板中将它们引入。这种代码通常像这样:
1 | <%= require('html-loader!./parts/footer.html') %> |
请注意,这里使用了相对路径写法。
正如你所看见的,这种操作需要 html-loader 的支持,如果现在项目中没有安装这个依赖,可以这样安装:
1 | npm i html-loader -D |
也许你很好奇,上面这种写法似乎并不像 HTML 的写法。的确,这其实是 EJS 的语法,从每一个 <%= 开头到 %> 结尾中间的内容,是可以被改变的,我们可以将它们理解为“变量”。那么,是谁会将值插入这些变量呢?其实是 HtmlWebpackPlugin 中的 templateParameter 字段。我们可以在这个字段中向 HTML 模板中注入我们希望的值,例如:
/path/to/test.template.html
1 | <title><%= title %></title> |
1 | const HtmlWepackPlugin = require('html-webpack-plugin'); |
如果不出意外,我们也许可以看到下面的输出结果:
test.html
1 | <title>Hello, world!</title> |
选择服务端渲染模板引擎
在服务端渲染时,我们可能也需要类似于以上的配置。不幸的是,Webpack 的某些插件已经使用了 EJS 的语法以传递数据。因此,我们已经无法使用 EJS 作为服务端渲染时的模板引擎了。不过,目前还有许多结构和 HTML 基本一致的模板渲染引擎,我们选择的是 Handlebars,因为这是结构最接近 HTML 的语法。我们可以写出下面的代码:
1 | <title><%= title %></title> |
Webpack 配置仍然沿用上一个例子。
如果不出意外,我们可能可以看到下面的输出结果:
1 | <title>Hello, world!</title> |
看到这样的结果,说明用于服务端渲染的插值依然还在,也就表明这种语法对于 Webpack 来说是“安全的”。
配置 HtmlWebpackPlugin
基于上文的探讨,我们大致可以得出一份可行的 HtmlWebpackPlugin 配置:
1 | ...entries.map((value, index) => { |
你也许会发现这段代码缺少一些上下文变量,如 config、pages 等。因为这段代码是直接从一个上线项目中拷贝来的。不过这并不伤大雅,而且之后的案例中还会使用这个案例的全部配置。因此,我们仍然不用过度关心这段代码的上下文,仅需理解每个配置项分别意味着什么。
进一步优化
我们已经将 Webpack 核心的配置都梳理出来了。现在,我们还需要对这份配置进行一些优化。优化的方法可以是下面提及的:
- 提取公共依赖
- 将 CSS 单独提取
- 将打包的 Bundle 上传至 CDN
- React Router 配合 React.lazy() 和 Suspense
中的一种或多种。但是具体的优化步骤由于篇幅所限,不做详细阐述。
中间层配置
在选择中间层用何种语言(或技术)时,笔者选择了 Node.js (平台)和 Koa.js (框架)进行中间层开发。原则上,中间层的选择搭配可以是随意的,例如 Java、Python + Flask 等。但是笔者推荐的还是基于 Node.js 平台的框架,因为 Node.js 使用的语言仍然是 JavaScript,因此,我们编写中间层的学习成本和重构成本是极低的。
koa-views
不同于 Express.js,Koa.js 并不原生提供渲染引擎。因此,我们需要安装 koa-views 赋予 Koa.js 渲染 HTML 模板的能力。
1 | npm i koa-views @types/koa-views -S |
我们可以在服务端代码中编写如下的代码:
/server/index.ts
1 | import views from 'koa-views'; |
这段代码指定了要在当前目录父级目录下的 server-templates 中指定的模板。如果我们的项目中存在 /path/to/project/server-dist/index.html,则可以通过下面的代码找到它,并将它渲染出来:
1 | import Router from 'koa-router'; |
这并非 Koa.js 原生的语法,而是
koa-router路由匹配的语法。若你希望对它有进一步的了解,请移步 koa-router - npm。
代理转发 Ajax 请求
在 Node.js 服务端程序中,代理某些请求通常可以使用 http-proxy-middleware 的中间件(请注意,这里的“中间件”并不是上文提及的“中间层”)。但在 Koa.js 中,我们并不能直接使用它作为代理转发请求。我们还需要将它包装进 koa2-connect 中。我们的代码应该像这样:
1 | app.use(async (ctx, next) => { |
前端代码目录结构
也许你已经注意到,Webpack 中对路径扫描生成入口列表的方式已经决定了我们的前端目录结构应该要遵守某种约定。在这个实例中,我们通过阅读 Webpack 配置可以了解到:Webpack 将会扫描 /src/page 目录下所有包含 index.tsx 文件的目录,根据指定的相对路径根目录(即 getEntries() 的第二个参数,我们使用了 /src/pages)计算出对应的路由(例如:假设存在 /src/pages/test/hello/index.tsx,那么从它计算出的路由是 test/hello)。
在每个包含 index.tsx 的目录中,index.tsx 应该像这样:
1 | import React from 'react'; |
因此,我们也许可以得出这样一个结论:/src/pages 目录下的每一个子目录,包括它本身,都是一个独立的入口,而每个入口也可以是一个独立的 React App。
编写代码
首页
/src/pages/App.tsx
这个页面将会向中间层的 /api/users 发送一个 Ajax 请求。显然,此时的 Ajax 请求是经过中间层代理转发的。同时,我们也许可以发现,这个页面并没有使用服务端渲染,而是通过中间层直接渲染出来的。因为这个页面没有必要做服务端渲染,也无法使用服务端渲染。
1 | import React, { useState } from 'react'; |
用户 Gist 列表页面
/src/pages/user/App.tsx
1 | import React from 'react'; |
/src/templates/user.html
1 |
|
/server/routers/index.ts
1 | import Router from 'koa-router'; |
这个页面稍微有点复杂,无论是中间层的路由逻辑还是 HTML 模板。但是你可能已经发现,和首页不同的是,/src/pages/user/App.tsx 中的代码其实非常少,这是因为这个页面完全使用了服务端渲染,因此它的 React.js 逻辑(也就是前端逻辑)非常简单,而 HTML 模板和路由逻辑稍微复杂一些。
构建
笔者在模板中预置了我们可能需要的 npm 脚本。
现在,我们需要使用构建命令将前端代码通过 Webpack 打包编译,以及将使用 TypeScript 编写的中间层代码编译为 JavaScript 代码(这并不是必须的,因为几乎所有持久化产品(如 nodemon、pm2、forever 等)都支持直接运行 TypeScript 代码)。
1 | npm run build |
打包编译仅需数十秒的时间。完成之后,我们可以在项目根目录下看见一个名为 dist 的目录,里面的内容可能像这样:
1 | . |
展示
现在,我们已经有了打包编译后的所有文件。为了启动测试用的服务器,我们应该执行
1 | node dist/server/index.js |
如果没有在系统环境变量中指定 PORT 的值,它将会在 127.0.0.1:5000 启动一个 Node.js 服务器,也就是所谓的中间层服务器。
我们直接访问 http://localhost:5000,页面也许像这样:
我们也可以看一看首页路由究竟返回了什么:
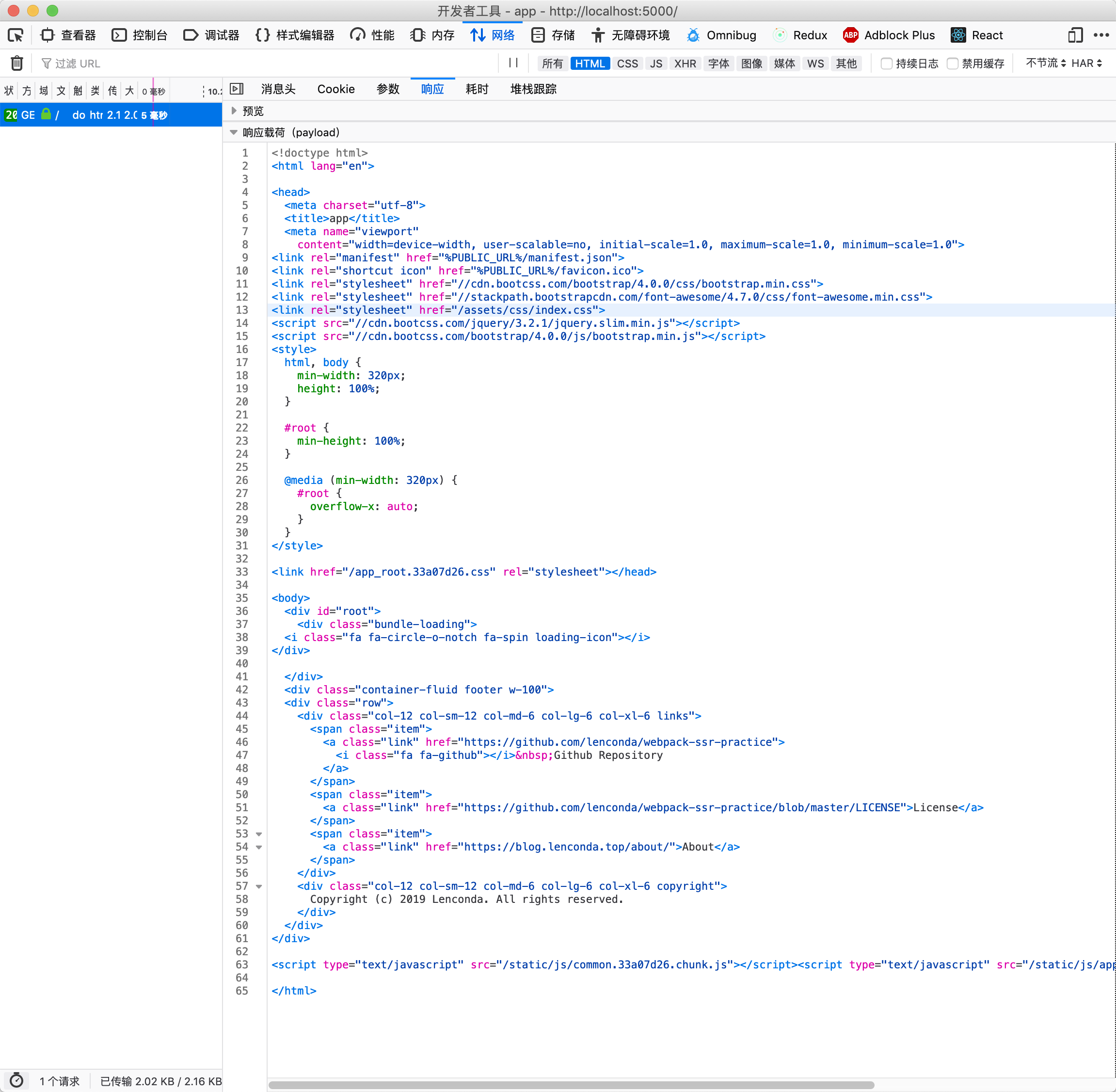
我们并不能直接在返回的 HTML 中找到首页上的视图。因为视图都是通过 HTML 末尾处引入的 Bundle 渲染的。前文中,我们已经知道,这是因为这个页面并没有使用服务端渲染。
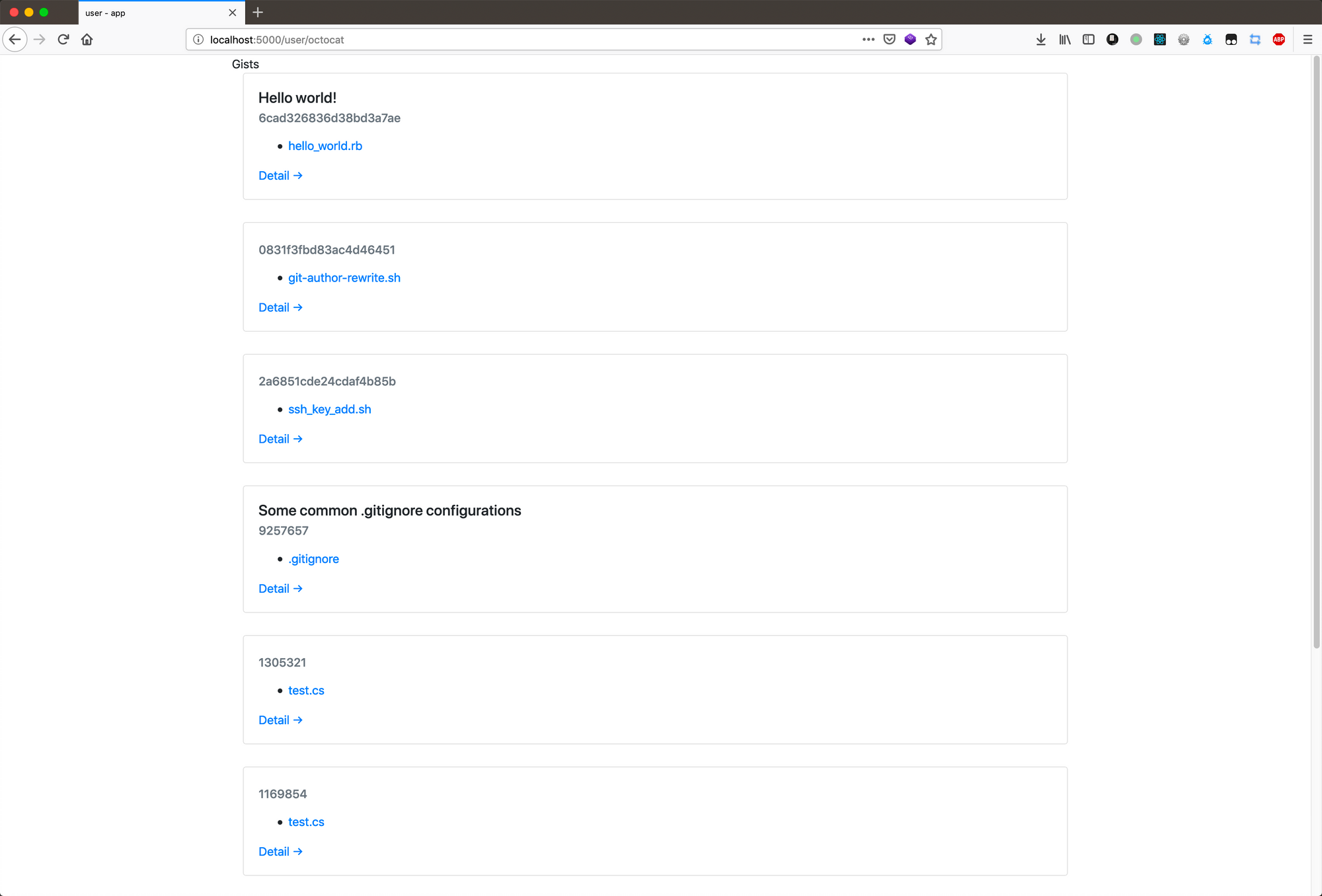
我们再来看一看用户 Gist 页面。我们在首页输入 “octocat”,点击 “Search”,稍等一会,页面就会跳转到 /user/octocat:
此时,中间层的 Ajax 代理捕获了一个由客户端发送给后端的 Ajax 请求:
那么现在,我们看一看这个路由返回了什么:
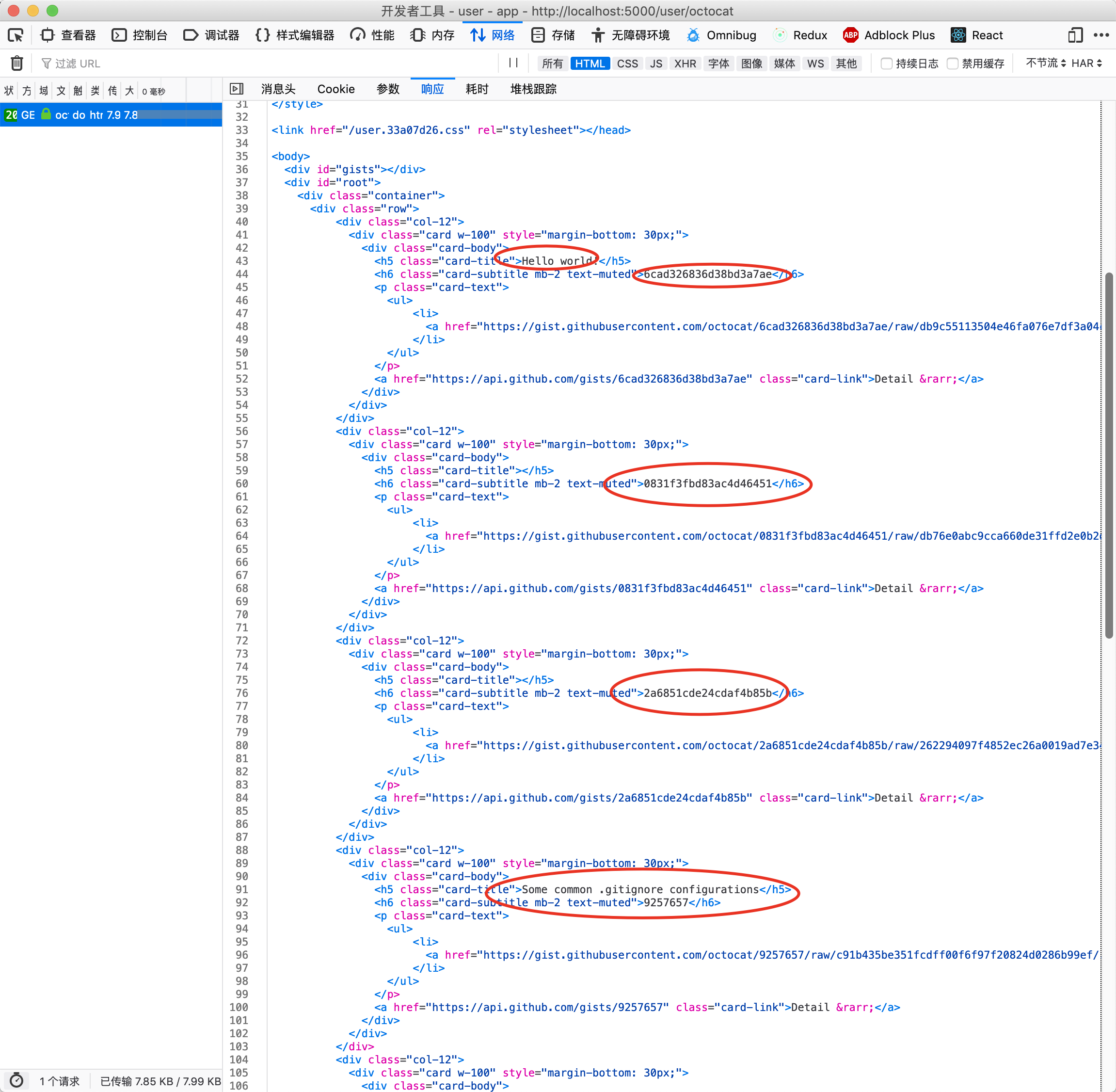
我们发现,用红色墨迹圈出的部分是已经在服务端渲染出来的。
更完整的实例
笔者使用本文讨论的方案构建了一个简单的 Web 应用,目前已经在线上运行了。这个应用的页面很少,其中使用了服务端渲染的页面也非常少(因为大部分页面实在没有使用服务端渲染的必要,也不希望被搜索引擎爬虫抓取),但是笔者认为它完全可以体现这篇文章的核心思想。
总结
到此为止,我们已经达到了我们所要讨论的预期目的:使用 Webpack 的多入口特性,生成可以用于服务端渲染的模板,进行服务端渲染。和大部分现有的方案不同的是,我们使用了更“另类”的方式:尽最大的努力是中间层以原生(在本文中指的是 Koa.js 的模板渲染引擎),而无需考虑如何针对特定的前端框架同构(如 Next.js 之于 React.js、Nuxt.js 之于 Vue.js 等)。
仍然存在的疑惑
即使我们“大费周章”地将这套方案详细地讨论,疑惑仍然还是存在的。笔者将这套方案分享给身边的朋友时,他们几乎都没有马上理解和完全接受。不过,他们提出的问题也许非常有价值。我们不妨来帮忙解答其中的一些问题:
为什么要使用 React.js 作为前端框架?我可不可以用 Vue.js / Angular / 原生 JavaScript 编写前端?
笔者选择 React.js 作为前端框架是因为个人喜好。当然,完全可以其他任何框架甚至原生 JavaScript。因为中间层只需要 HTML 模板进行渲染,而我们则是通过 Webpack 打包编译的。Webpack 多入口和任何框架都没有关系,不论是用 React.js、Vue.js 还是 Angular,只要前端逻辑一样,它们打包编译出来的代码也几乎完全一样。因此,我们可以随心所欲选择自己喜爱的技术编写前端代码。
既然都已经有中间层渲染页面了,为什么还要多此一举再去用 Webpack 打包出的 Bundle 加载剩下的数据?
因为在真实的项目中,我们不可能完全依赖于服务端渲染,也不可能完全靠客户端渲染。我们必须明白一个最核心的原则:对于我们希望搜索引擎爬虫爬取的内容,我们应该尽可能地使用服务端渲染;对于我们不希望,或者没必要被搜索引擎爬虫爬取的内容,我们应该尽可能地使用客户端渲染(即 Ajax 方式)。因此,我们需要服务端渲染我们想要渲染的数据,再将带着 Bundle 的渲染完毕的 HTML 发送给浏览器,由浏览器继续执行 Bundle 加载剩下的数据和视图。
服务端渲染难道不是指后端从数据库取出数据再渲染吗?为什么还有个中间层?它属于前端还是后端?
服务端渲染中的“服务端”并不是真正的后端,它是无法接触到数据库的。它充当着客户端与后端的“联络员”。在同构时,后端不需要经过任何更改。中间层属于前端。
参考资料
- 《深入浅出 Webpack》
- webpack多入口文件页面打包配置- 掘金
- webpack4.x实现Js和Html多入口、多出口以及html-webpack-plugin插件实现html各自引入各自的js文件 第三节
- webpack多入口文件页面打包配置
- Webpack 4 course – part four. Code splitting with SplitChunksPlugin
- Webpack4+react多页面架构- 作品- React 中文
- HtmlWebpackPlugin | webpack
- HtmlWebpackPlugin用的html的ejs模板文件中如何使用条件判断
- Webpack实战-构建同构应用
- 从零开始搭建React同构应用(三):配置SSR
- React服务端渲染(项目搭建)
- Documentation - Getting Started | Next.js
- 使用Next.js构建React服务端渲染应用
- react + express + webpack 搭建 React SSR(一)
- Server Side Rendering - SurviveJS
- React 中同构(SSR)原理脉络梳理- 掘金
- React 服务端渲染与同构- 前端- 掘金
- React 同构直出优化总结| AlloyTeam