在现代编程语言中,我们经常提及面向对象编程(Object-Oriented Programming,OOP)。所谓的面向对象,其实是一种具有对象概念的程序编程典范,同时也是一种程序开发的抽象方针。与函数式编程(Functional Programming,FP)不同,面向对象编程希望把所有的事物都认为是一个对象,而对象可以通过实例化一个类或继承一个对象而获得(函数式编程认为一切皆函数,一个确定的输入对应一个确定的输出,并且不会产生副作用)。
面向对象通常可以采用两种方式实现:prototype 或 class。JavaScript 中对象的实现显然属于前者,而后者的代表性语言有 Java、C++、TypeScript(TypeScript 同时支持这两种方式) 等。
本篇文章将会简单地梳理 JavaScript 中的相关问题。读完本文,您应该能了解到包括但不限于以下内容:类与对象、对象创建的几种模式、对象继承的几种模式、对象方法的重写和重载在 JavaScript 中的实现。
前置知识
如何理解类和对象
类是一类事物的抽象概括,它可能包含数据的类型和对数据的处理方法。对象是某个类的实例化。一个生动的例子也许可以帮助我们加深对它们的理解:生物学家会将地球上的生物划分为界、门、纲、目、科、属、种等层面,那么一个类可以是这些层面的一种,用于描述某个层面的生物所具有的独特属性。例如芹菜和胡萝卜同属伞形科植物,仔细观察您也许会发现胡萝卜的茎叶与芹菜的茎叶形态十分相似。在这个例子中,伞形科是一个类,而芹菜和胡萝卜是这个类的实例化,也就是对象。
对象是程序的基本单元,将程序和数据封装其中,以提高软件的重用性、灵活性和扩展性,对象里的程序可以访问及经常修改对象相关连的数据。在面向对象程序编程里,计算机程序会被设计成彼此相关的对象。
函数和方法
当我们在向身边的人闲聊这些问题时,往往会在不经意间将函数和方法混为一谈。虽然在大部分情况下无伤大雅,但是您必须明白函数和方法有根本上的区别。在 JavaScript 中,函数可以以如下几种方式表示:
1 | // 1 |
一个函数可以被认为是一个代码块(Code Block),从 JavaScript 解释器的角度上说是一个块级作用域,这个作用域在执行时会执行函数内部的代码,有的时候会根据传入的形式参数处理出一些结果。处理出的结果可能会在函数体内部返回出来。而方法通常指类或对象中的函数,它往往会依赖类或对象中的一些属性或其他方法。例如在 JavaScript 中:
1 | Date.parse(); |
即使它是一个静态方法,但它仍然是一个方法:它不能脱离 Date 而独立存在。
特性
我们将会在下文中探讨面向对象的三大特性——封装、继承和多态,以及如何在 JavaScript 中使用它们。
封装(Encapsulation)
所谓封装,是指面向对象的编程语言中隐藏了某一方法的内部逻辑或某一属性的值。对象只对外提供与其它对象交互所必需的接口,我们只需要关注如何使用,而不需要关心这些方法和属性究竟是什么。上一个例子中我们提到了芹菜,我们再向下细分,仍然可以将芹菜的器官作为划分对象的最小单位。它在发育果实时,身体中的某个器官会生成某种激素,用于加快果实的发育。果实作为一个对象,只需要使用激素,而不需要关心激素是如何产生的,更不会参与激素的产生。
于是,封装的优势就十分明显了:
- 对内部数据起到一定的保护作用
- 提高内聚,降低耦合(可以被多种对象复用)
在 JavaScript 中,封装可以通过下文中几种方式实现
函数模式:非严格意义的封装
最简单的封装策略是通过一个立即执行函数(IIFE)和闭包(一个记住了自己所在的块级作用域的函数)的特性返回一个对象字面量:
1 | const foo = (function() { |
我们给 foo 赋予了一个 IIFE,它将立刻执行并返回一个函数,这个函数将会返回一个对象,对象中 bar 的值由块级作用域中的 bar 和 foo 的形式参数 baz 共同确定。
字面量模式:最简单的封装模式
顾名思义,字面量模式指的是 JavaScript 允许我们直接用 {} 定义一个对象。在 JavaScript 中,对象是使用一个散列表存储数据的,根据对象的键名生成对应的哈希,从不连续的内存空间(堆)中寻找到对应的值。通过字面量模式,我们可以直接创建一个对象。通过这种方式创建的对象并没有显式地实例化一个类,但它确实是 Object 的实例——这也是它的独特之处。
1 | const foo = { |
通过上面的代码我们可以创建一个名为 foo 的对象,其中包含了一个属性 bar。现在,我们希望使用 foo 实例化 2 个对象,于是,我们应该可以写出下面的代码:
1 | const foo1 = {}; |
尝试运行上面的代码,我们可以确认这段代码确实可以帮助我们得到两个 foo 的实例化对象。但事实并非如此。虽然 foo1 和 foo2 的字面量都相同(它们都有名为 bar 的属性,并且都是 string 类型),但是它们都不是 foo 的实例:**foo1 和 foo2 都没有和 foo 建立任何关联**。字面量模式创建对象的过程非常简单,但是它暴露出的问题也十分明显并致命:
- 对象无法和类产生关联
- 若需要批量创建相同规格的对象,将会非常麻烦
工厂模式:改进的字面量模式
工厂模式将定义一个函数,这个函数将创建字面量的过程抽象出来了:
1 | function createFoo(bar, baz, fuz) { |
我们可以发现,尽管 createFoo 函数将 foo 的创建过程抽象了,但函数内部仍然按照字面量模式创建了一个临时对象,将这个对象的属性值设置为相应的形式参数的值,最后再返回这个对象。此方法虽然解决了批量实例化对象时给编程人员造成的困扰,但最关键的问题仍未解决。
构造函数模式:将对象与类联系起来
一个典型的构造函数模式往往像下面这样:
1 | function Foo(bar, baz, fuz) { |
也许您会认为构造函数模式与之前的工厂模式很相似,但实际上并非如此。构造函数模式并不会显式地创建一个对象,而是将需要设置的属性和值赋予 this。当我们希望创建 Foo 的实例时,我们通常可以这样做:
1 | const foo = new Foo('fiz', 'buzz', 'lorem'); |
这样做的精妙之处在于使用 new 调用 Foo 时,Foo 将作为一个构造函数被调用。那么在这个过程中究竟发生了什么呢:
- 创建一个新的对象
- 将这个新的对象的
[[Prototype]]指向构造函数的[[Prototype]] - 将
this绑定到这个对象上 - 返回这个对象
尽管通过 new 调用构造函数的过程十分清晰,但是我们还是有必要对其中的某些概念进行探讨。
理解 this
在其它语言中,this 通常用于在类中指代这个类本身,我们往往可以通过这个关键字调用类自身的属性和方法。但是,在 JavaScript 中,这个关键字在函数里也能被访问(这也证明了函数在运行时确实是一个对象)。
通常,this 永远指向调用这个函数的对象(或这个函数所在的运行时作用域)。this 在词法阶段是无法确定的,也就是说我们不能通过词法作用域判断某个函数中 this 的指向。我们可以分几种情况讨论:
直接调用
1 | function foo() { |
直接调用时,函数中的 this 将指向直接调用它的对象(如 window)。是的,在严格模式下 this 的指向可能是 undefined,但这显然不是本文要讨论的问题。如果您仍想了解这一有趣的现象,请翻阅:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Strict_mode
作为对象方法调用
1 | function bar() { |
作为对象方法调用时,this 指向调用它的对象。
作为构造函数调用
1 | function Foo() { |
作为构造函数调用时,this 指向通过 new 返回的新对象。
通过 call、apply 和 bind 改变
这三个方法本质上并没有区别。call、apply 与 bind 的区别在于调用前者会立即执行,而调用后者则会返回一个改变了作用域的函数。
1 | const foo = {}; |
理解原型和原型链
在上文中,我们了解到 JavaScript 通过原型实现面向对象。对此,JavaScript 设计者提出了一个规范的名称:[[Prototype]] 用于描述实例的原型对象。现代化浏览器几乎都实现了这个规范,并将其命名为 __proto__。
每个函数都有作为构造函数的潜质,因此每个函数都有一个隐式的 prototype 属性,指向这个函数的原型对象。所谓的原型对象就是一个隐藏的实例,这个实例被用于建立构造函数和实例的联系。实例中的 __proto__ 也指向这个原型对象。于是,实例和构造函数的关系就建立起来了。简而言之,__proto__ 永远指向构造函数的原型对象,也就是构造函数的 prototype:
1 | function Foo() {}; |
如果我们把 Foo 也当作一个 Function 的实例,那么 Foo.__proto__ 和 Function.prototype 指向的是同一个对象。
基于上述的关系,一个对象往往可以通过不断使用 __proto__ 属性追溯到最根源的原型对象上。这个原型对象就是 null,这种关系被称为原型链:
1 | function Foo() {}; |
下面这张图也许能帮助我们更深入地理解原型链:
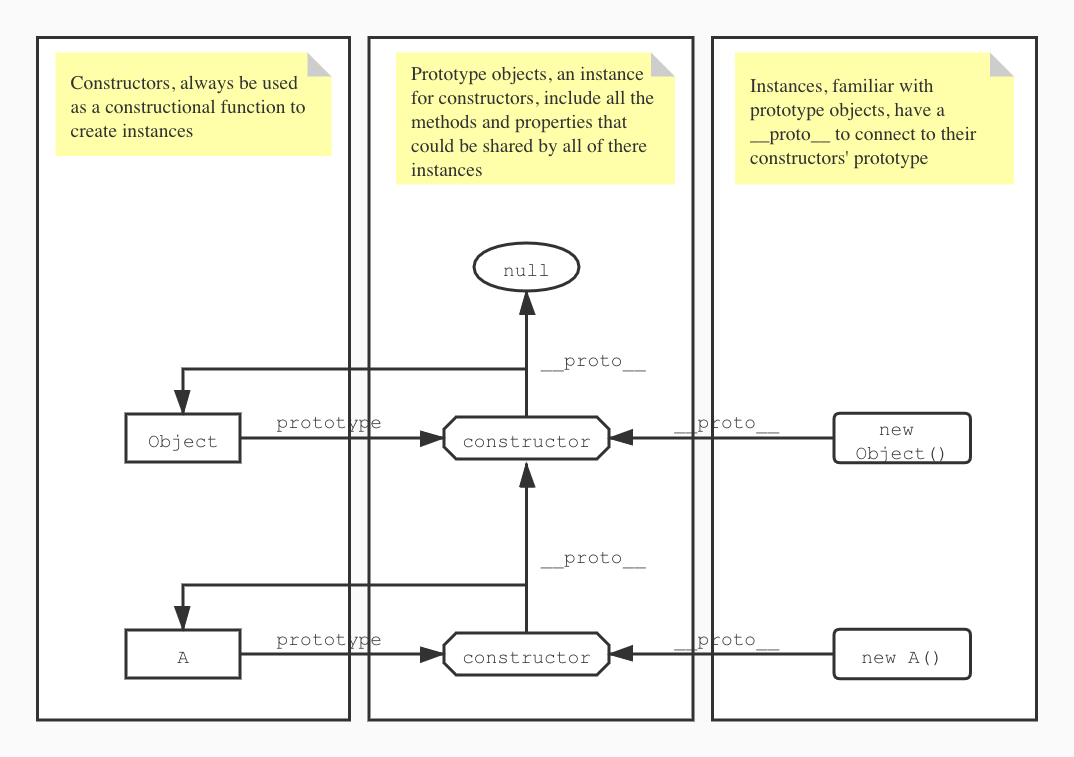
原型模式:构造函数模式的优化
在上文中我们已经明白了原型对象和原型链的基本概念,因此,我们可以进一步通过原型优化类的封装。我们已经知道,prototype 实际上是一个指针,这个指针永远指向这个函数的原型对象。通过对上一节例子的观察我们可以发现:我们每实例化一次,就会为新的实例创建一个新的 saySomething 方法,但是我们并不希望每个 saySomething 方法都不一样(或最好一样)。于是,我们可以通过直接在 prototype 上定义一个方法或属性的方式完成优化:
1 | function Foo(bar, baz, fuz) { |
我们可以将一些不会更改的属性和方法使用原型模式设置,这样,每个实例都有一个独一无二的原型对象的副本,也能一定程度地共享方法的引用,避免对堆内存资源的不必要的占用。
值得注意的是,若一个属性或方法存在于构造函数原型对象上,当我们以后修改这些属性值或方法时,通过该函数构造出的所有对象的相应的属性值或方法均会被改变:
1 | Foo.prototype.a = 1; |
继承(Inheritance)
继承更像是一种家族关系。我们一般会把 B 从 A 获取了一些属性或方法的现象叫做“B 继承自 A”,那么 A 就相当于 B 的父级类,简称“父类”。同样地,在开篇的例子中,我们通过生物学中的概念理解类和对象:芹菜和胡萝卜同属于伞形科,但芹菜属于芹属,胡萝卜属于胡萝卜属,这两个属的共同父类是伞形科,也就是说它们都继承了伞形科的特征(叶片形状、花序、种子形态等)。同样地,比科更广的是目,所以目是科的父类,属于同一目的生物也都有一定的共同特征,它们的共同特征都来自于这个目所赋予的属性和方法。随着不断向父类追溯,父类会变得越来越抽象(共同特征越来越少):生物学中父类的起点是界,动物界和植物界是占比最大的两个界,动物和植物的共同特征非常少(细胞层面以上的共同特征更是屈指可数)。
在编程语言中,继承也是如此。最抽象的类一定是继承的起点。在 JavaScript 中,继承的起点是 null, Object 直接继承自它。我们所熟知的继承,一般是从 Object 开始的。如果我们使用字面量模式创建一个对象,那么这个对象就继承自 Object。
基于上述的认知,我们能够开始讨论 JavaScript 从 Object 的子类继承的方式了。
原型链继承
原型链继承将子类的原型对象指针指向父类的实例:
1 | function Person(name, age) { |
不难发现,我们将 Man 的原型对象指向了父类 Person 的实例,因此,Man 继承自 Person。但是这并不是最理想的继承方式:虽然 Man 继承了 Person,但它的原型对象其实是 Person.prototype,子类在实例化过程中并不能向父类传递参数。所以这种方式并未实现真正的继承。
我们也许可以从下图中理解原型链继承:
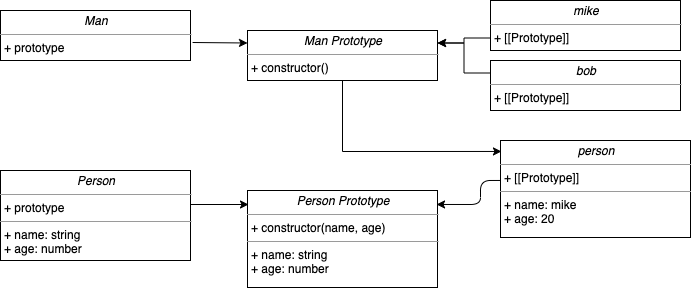
经典继承(借用构造函数)
经典继承在子类中调用父类构造函数的 call 方法(apply 同样也可以):
1 | function Person(name, age) { |
经典继承的核心思想就是通过 call 改变 this 的指向达到继承的目的。这种方法看似实现了完美的继承,实则不然:
1 | mike.__proto__ === Person.prototype; // false |
子类的原型对象并不是指向父类的:并没有显式地为 Man 的原型对象指向 Person 的实例。因此,通过经典继承得到的子类的原型还是指向自身,prototype.constructor 属性却指向父类构造函数 Person 本身:
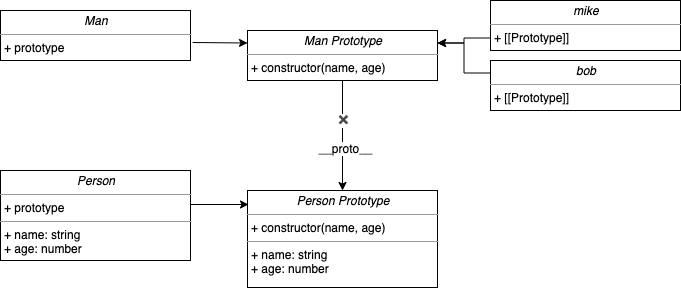
因此,我们需要结合经典继承和原型链继承的优点,进一步完善继承机制。
组合式继承
上文提到,我们需要结合前两种继承方式。因此,我们提出了“组合式继承”。
1 | function Person(name, age) { |
组合式继承解决了经典继承中原型链断裂的问题:
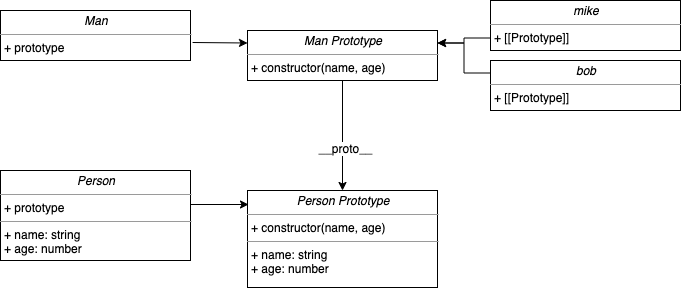
原型式继承
不同于原型链继承,原型式继承通过调用 Object.create 方法实现继承:
1 | function Person(name, age) { |
我们注意到,mike 和 bob 中的属性来自于父类的原型对象中,并不是真正属于自己。这通常会导致原型指针混乱而造成 this 指向不明的问题。
寄生组合式继承
寄生组合式继承对组合式继承进一步优化:简化了在更改子类原型对象指向时调用的父类构造函数。我们不难发现,在组合式继承中,当我们希望修改子类的原型对象指向时,通常需要指向父类的实例,这就导致了父类的实例需要被调用两次(第一次在子类构造函数内)。我们结合组合式继承原型链清晰的优点和原型式继承的不需要调用父类构造函数的优点,再次组合:
1 | function Person(name, age) { |
寄生组合式继承是目前使用最广泛的继承方式。
混入式继承
混入式继承遍历父类的所有属性,并赋予子类。
ES 6 extends
使用 extends 关键字可以实现从父类继承,但它只是语法糖,其本质仍然是以上组合方式中的一种。
多态(Polymorphism)
顾名思义,多态意味着某个方法在不同的条件下会选择不同的动作。多态性包括以下两种特性:
- 重写(Overwrite):允许子类对方法的实现重写,但签名、形式参数列表和返回值类型都不能改变
- 重载(Override):允许子类改变方法的形式参数列表、返回值类型,但不允许改变签名,在调用方法时,根据输入的形式参数选择对应的重载
回到之前的例子中:芹菜和胡萝卜的属性有一部分继承自伞形科,但是芹菜和胡萝卜最大的不同是胡萝卜会形成块状的橘红色根茎,而芹菜不会形成,但这种现象不允许输入的形式参数(土壤、光合作用、矿物质等)和返回值(根茎)是不同的。所以这两种植物在根茎基因表达上的不一致属于重写;在温度、阳光等条件适宜的情况下,芹菜会分化出花蕾,而恶劣条件下的芹菜可能一直都无法分化。这种现象则是重载。
重写
在 JavaScript 中,重写现象非常常见。您也许听说过这种说法:
在判断引用类型时,我们通常不希望直接用
toString方法,应该用Object.prototype.toString.call方法判断
正是因为有些类(比如 Array)会重写 toString 方法以方便编程人员获取希望的字符串,而不是枯燥的 [object Object]。
JavaScript 的重写机制十分方便。在单页面应用中,我们通常使用 window.history.pushState 管理前端路由。不幸的是,这个方法并不会触发任何的事件。但是我们仍然可以使用重写的方式实现路由变换时的监听:
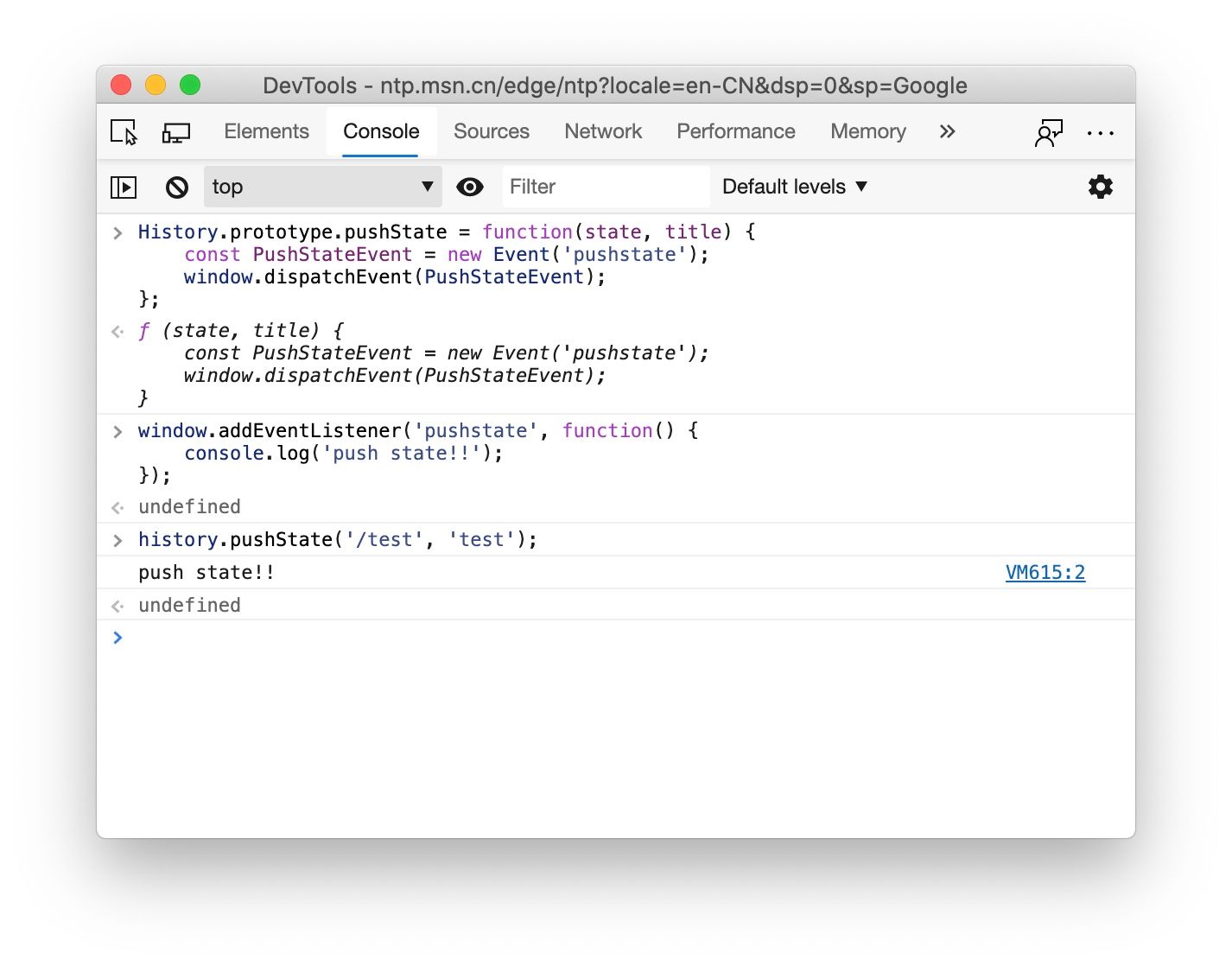
重载
很遗憾,JavaScript 并没有提供重载的实现。这是因为在 JavaScript 中,函数是指针,如果定义了多个同一签名但形式参数列表不同的函数,后面的同签名的函数会覆盖前面的函数(似乎仍然是重写)。
即便如此,我们仍有办法解决重载的实现。笔者通过判断 arguments 对象的长度来区分同签名的重载函数。我们可以定义一个 overridable 函数,返回一个拥有如下数据结构的对象:
1 | function overridable() { |
在上面的数据结构中,functions 可能让人迷惑:为什么它是一个元素为函数的数组?因为我们在实现的重载功能中,保存函数是通过函数形式参数列表长度实现的,也就是说当我们调用 add 时,会将 functions 中 index 为当前传入函数的形式参数列表长度的元素设置为当前函数:
1 | // add(fn); |
为了能够链式地调用add,add 最终会返回上述的数据结构:
1 | // add(fn); |
以下代码便是 add 的全部代码:
1 | add: function(fn) { |
前面提到,当我们添加完所有可能的重载函数后,我们需要调用 result 方法返回一个函数。为了保存所有重载函数的列表,我们需要在 result 中再返回一个闭包函数:
1 | result: function() { |
因此,我们能够在这个闭包函数中通过传入的形式参数列表从 functions 中选取合适的函数执行。
您可以从下面的代码中回顾我们是如何实现 overridable 的:
1 | function overridable() { |
使用案例:我们希望实现一个 foo 函数,当传入三个参数时,返回它们三者的和;当传入一个参数时,返回参数的平方:
1 | const foo = overridable() |
虽然我们已经实现了 JavaScript 中函数的重载,但我们的 overridable 并没有经历过严格的测试。这意味着我们无法保证未来 overridable 会出现怎样的问题,或者说我们目前并没有通过测试证明它在所有边界情况下仍然能保持正确的逻辑。因此,请不要将它用于真实的生产开发环境中。。
目前,笔者已将上述代码打包成 NPM 依赖,可以通过 npm i overridable 安装依赖并测试,并在 lenconda/overridable 上开放其源代码。如果您有兴趣完善这份代码,请按照 README 的要求贡献代码。