在 Philip Roberts 眼中,JavaScript 是一门单线程、异步、非阻塞、解释型脚本语言。我们在享受 JavaScript 异步编程带来的便捷的同时,也在为如何处理异步(或处理异步带来的冗杂的代码)而苦恼。但是,作为一门富有活力的编程语言,JavaScript 也在不断地完善自己的标准与规范,为众多 JavaScript 开发者解决这些苦恼。当我们在谈论如何处理异步时,我们可能会立刻想起回调函数(Callback Functions)。我们可以通过这种神奇的机制完成对每一个异步操作结果的处理。然而,随着我们的代码越来越复杂,异步操作也越来越多,而原始的回调方式暴露出的问题也越来越明显。
好在,Promise 的到来为我们解决了一部分问题。那么究竟是什么使 Promise 具有如此魅力,使得它一度被称为“下一代”异步编程方案呢?我们将在本文中从源码和底层原理层面探讨这些问题。在阅读这篇文章前,我们需要掌握以下内容:
- JavaScript 事件循环机制
- 异步编程的基本概念
- JavaScript 中回调函数的概念
- Promise 规范以及基本使用方式
回调:从刀耕火种的时代说起
我们为何需要回调?因为 JavaScript 是一门事件驱动的语言。这意味着事件驱动将赋予 JavaScript 异步非阻塞的特性,即 JavaScript 的执行并不会因为要等待某个事件的响应而中断当前的运行。每个异步操作似乎都是独立于当前线程运行的。那么,异步代码执行完成之后应该怎么办?“主线程”怎么知道它已执行完成?因此,我们需要一个回调函数帮助我们实现它:在同步代码中定义一个函数,这个函数将作为异步函数中处理结果的回调函数,被我们作为形式参数传入异步函数中:
1 | function callback(result) { |
尽管上面的代码毫无实用价值,但它却能够帮助我们理解回调函数的作用:在同步代码中注册一个函数作为回调函数,形式参数可以是任意的。在异步函数中使用时,我们可以调用传入的回调函数,并且将我们希望的结果传给它。于是,在同步代码中,这个回调函数其实已经被调用了,并且成功地拿到我们传给它的结果。如果观察仔细的话,我们也许能在很多场合中发现回调的踪影:
封装 XMLHttpRequest:
1 | function ajax(method, url, onsuccess, onerror) { |
作为事件监听器:
1 | window.addEventListener('scroll', function(event) { |
回调并不完美
回调虽然能帮助我们解决这一大难题,但它给我们带来的困扰的确是存在的。假设我们现在仍然没有找到规避回调带来的问题的方法,也许我们会面临包括但不限于下面这些问题:
在上文中,我们了解到回调经常出没于对异步请求的处理中。假设我们需要依次请求 http://foo.example.com/1、http://foo.example.com/2、http://foo.example.com/3、http://foo.example.com/4,并且后一个请求的数据依赖于上一个请求的结果。我们也许可以写出如下代码:
1 | ajax('get', 'http://foo.example.com/1', function(data1) { |
我们为了实现上述的功能将会编写出如此恶心的代码:不仅要在每个回调里进行下一个请求的处理,同时还要对四个请求分别进行错误处理!我们将与之类似的情况称为“回调地狱”。
它带来的问题主要包括但不限于:
- 无法在复杂的业务场景中表达清晰的逻辑:正如我们所见,如果业务足够复杂,上述情况完全有可能发生。我们用于示例的代码也仅仅只是一个“模型”而已,如果在其中填入足够复杂的业务逻辑,那么当发生业务变更(例如:在第一次请求和第二次请求中增加一次新的请求)时,后面的回调函数中的变量的重新命名将会使我们头痛欲裂,甚至当我们接手一段复杂且庞大的异步函数时,我们根本无法掌控这个函数,也根本无法预测这段代码究竟是怎么执行的,在何时得到什么样的结果等等。因此,回调函数将有可能带来顺序的不确定性
- 控制反转:这本身是一种信任问题。我们认为一段可靠的代码应该对所有细节毫无死角地把控。那么,在回调中,我们一旦将复杂的业务逻辑交给异步函数中的回调函数处理时,我们将不能对整体和细节很好地把控:异步函数本身就可以认为是独立于同步函数的,或者是和同步函数并行执行的(实际上并不是),因此将原本属于同步的代码全部放入异步函数中,我们根本无法预测其中的某一个环节究竟会发生什么,假设其中的一环突然断裂(被错误中断),那么后续本该被执行的代码却一去不复返。因此,滥用回调很有可能会导致我们对控制权的转移或丢失
为什么回调地狱如此可怕:回调函数过多会导致代码难以预料,因为我们无法完全确定各个函数在什么时机被调用——没有人会喜欢这样的代码。
Promise,也许是“下一代”异步方案
在上文中,我们认识到了一个事实:虽然回调函数确实帮我们解决了很大的问题,但它本身的缺陷也十分明显,即顺序的不确定性和缺乏可信任性。如果我们仔细思考,我们也许能发现我们真正希望得到的结果其实只是将来这件事会得出结果,但是我们现在还没办法得到,但是我们十分希望它能够在未来这件事完成并得出结果后按照预期的顺序继续执行下面的事情。于是,为了解决上面的问题,我们想到,可以将这些事情封装在一个容器中,这个容器内部保存着几个状态,分别对应着已完成、未完成等,如果状态变化,将会通知我们。这样,既可以保证我们能够及时知道事情何时完成,也可以将事件完成之后对结果对控制权交换与我们。因此,Promise 应运而生。
揭开 Promise 的神秘面纱
前面提到,Promise 其实是一个保存着状态和结果的容器,容器内部还保存着一段未来才会结束的代码。Promise 是 TC 39 委员会制定的范式,它和我们所熟知的 Promise 存在着一些差别。我们在 JavaScript 中使用的 Promise 对象其实是 A+ 规范的实现,我们把这种规范称为 Promise/A+ 规范,但为了一般化,我们仍习惯于把它称为 Promise 规范。
Promise 规范有以下几个特点:
- 对象的状态不受外界影响:
Promise对象代表一个异步操作,有三种状态:pending(进行中)、fulfilled(已成功)和rejected(已失败)。只有异步操作的结果,可以决定当前是哪一种状态,任何其他操作都无法改变这个状态 - 只要状态改变一次,就不会再变,任何时候都可以得到这个结果:
Promise对象的状态改变,只有两种可能:从pending变为fulfilled和从pending变为rejected。只要这两种情况之一发生了,那么它将会一直保持这个结果
现在假设我们都已经明白了 Promise 规范的具体内容以及 Promise 的基本用法。接下来,我们开始通过完全从零实现一个 Promise 加深对它的理解。我们将我们创造的 Promise 实现称为 Undertake。
实现 Promise 规范
结构
我们首先要定义 Promise 容器的结构。我们已经知道,Promise 是一个可以被实例化的类,并且需要一个执行器(executor)作为回调接收成功信号(resolve)和失败信号(reject)的处理函数:
1 | function Undertake(executor) { |
状态、数据和回调队列
我们在上文中已经确认了,我们需要三种状态:pending(初始状态)、fulfilled 和 rejected:
1 | function Undertake(executor) { |
我们还需要存储结果或失败原因的数据结构 result 和 reason:
1 | // 成功的结果 |
最后,再添加上通过 .then() 注册的回调队列 resolvedCallbacks 和 rejectedCallbacks:
1 | _this.resolvedCallbacks = []; |
resolve(result: any): void 和 reject(reason: any): void
也许我们能够发现:当我们在 Undertake 的内部调用 executor 时,会将这两个函数以回调参数的形式传给使用者,这也是 Promise 解决了信任问题的原因。
1 | function resolve(result) { |
至此,Undertake 对 Promise 的实现在内部结构上已经基本完成了。
then(Function<any>): Undertake 和链式调用
Promise 规范中规定的链式调用可以通过 then 方法实现。这个方法存在于 Undertake.prototype 中。所谓的链式调用,实际上只是类似于函数式编程中函数调用链,then 将返回一个新的 Undertake 对象,并且立即 resolve(也许我们能很快发现,resolve 数据的来源其实是来自使用者提供的成功回调的返回值)。因此,我们才可以不断调用 then:
1 | Undertake.prototype.then = function(onfulfilled, onrejected) { |
catch(error: Error): void:处理抛出的异常
根据 Promise 规范,我们需要在 Undertake.prototype 中定义 catch 方法,用于处理过程中抛出的异常。我们很容易想到只需要使用 reject 事件的回调 onrejectd 函数就可以实现 catch:
1 | Undertake.prototype.catch = function(onrejected) { |
finally(Function): Undertake: 必有回响
如果我们熟悉诸如 try ... catch ... finally 之类的语句(不同的编程语言往往有不同的书写规范,但大体上实现的逻辑几乎一致),我们就应该很能理解 finally:无论我们的 Undertake 实例最终结果如何,finally 中的语句一定会被执行:
1 | Undertake.prototype.finally = function(callback) { |
静态的 resolve 和 reject
Promise 规范还规定需要存在静态的 resolve 和 reject,用于立即执行 resolve 和 reject。它们的用法可能是下面这样:
1 | Undertake.resolve(1).then(res => console.log(res)); // 1 |
即使是静态方法,它的返回值依然能拥有 then 链。因此,这两个方法的返回值依然是一个新的 Undertake 实例:
1 | Undertake.resolve = function(value) { |
all(Array<any>): Array<any>:Promise 之“门”
Promise 规范规定,我们必须实现一个“门”机制。所谓的“门”,其实是编程中的一个概念:遇到“门”时,等待相应但两个或多个任务都完成,“门”才能被打开,剩余但流程才能继续。虽然它们的完成顺序并不重要,但它们都必须完成。
在 Promise 中,这种机制的实现被称为 all:
1 | Undertake.all = function(promiseArray) { |
race(Array<any>): any:竞态
Promise 规范规定,我们需要实现一个“门闩”作为 Promise 的竞态机制,其输入和 race 一致,但只会响应第一个完成的结果:
1 | Undertake.race = function(promiseArray) { |
完整的实现
至此,我们已经将 Promise/A+ 中所规定的方法和状态全部实现了。通过下面的代码我们可以回顾我们实现整个 Undertake 的过程:
1 | /** |
Promise 定义的未来,已来
Promise 所在的提案在 2015 年被通过,也就是说,Promise 规范已经被包含在 ES 2015(ES 6)以上的版本中了。在过去很长的一段时间内,大部分网页浏览器都还不支持 Promise 的实现,或者没有完全实现。如果我们需要使用这一新特性,可能需要通过 Polyfill 才能获得完全支持。
现在是 2020 年 3 月,距离 ES 2015 发布已经过去 5 年了。我们可以看一看目前的浏览器对 Promise 规范的支持程度:
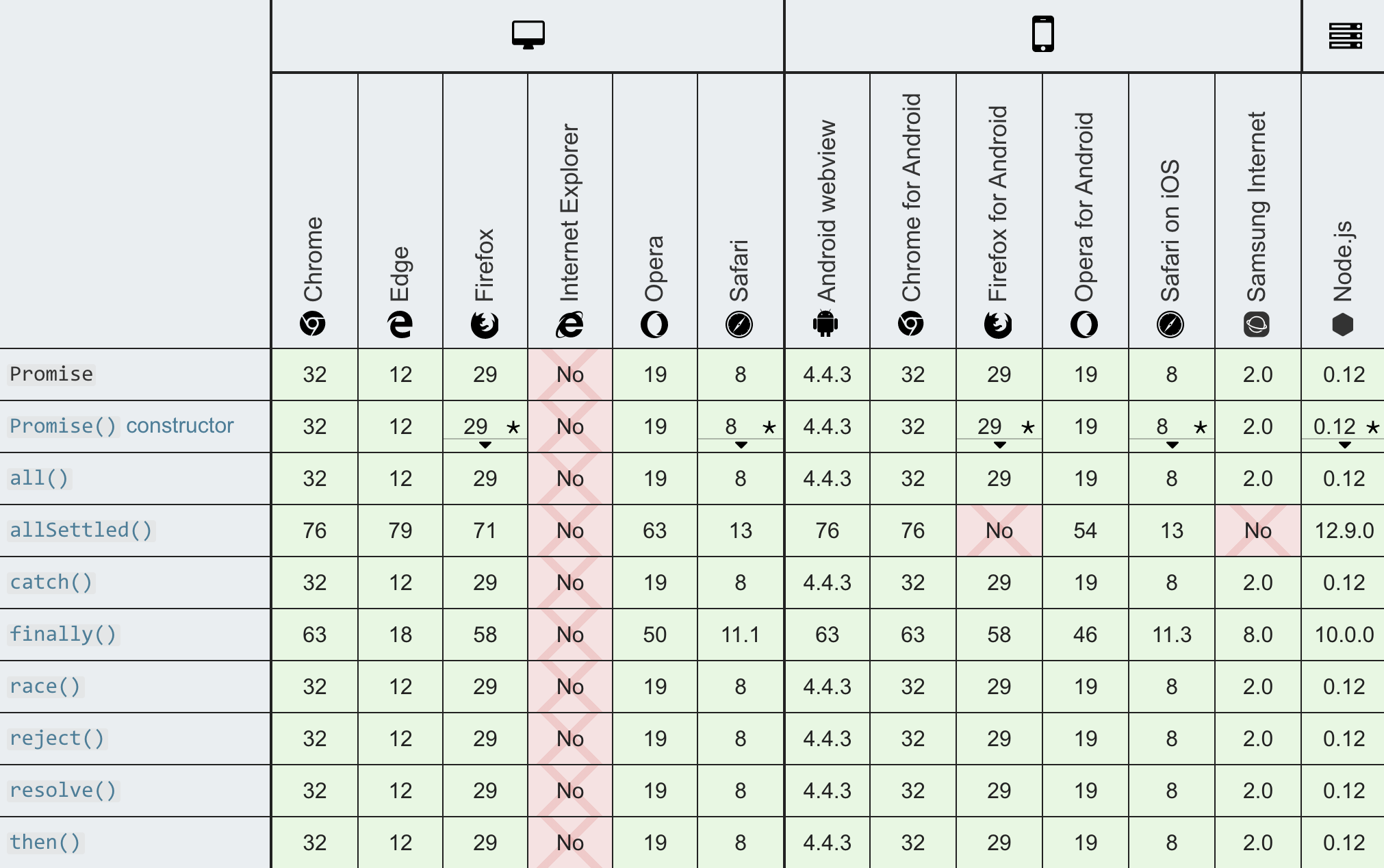
意料之中,除了 Internet Explorer 之外,绝大多数浏览器,无论是 PC 端还是移动端,对 Promise 规范对支持已经完全达到可以应用于生产中的水准了。因此,Promise 定义的未来,已经完全到来。
“未来”的未来
在 ES 7 规范中,async 和 await 被提出。这是一种比 Promise 更优雅的异步处理方案。async 函数允许隐式地返回一个 Promise 的实例。它融合了 Promise 和 Generator 的优势,比 Promise 本身更具有 JavaScript 未来异步方案中“独当一面”的潜质。虽然这是一种语法糖,但通过 Polyfill,我们依旧可以使用它写出更优雅的代码:
1 | async function foo() { |
在异步处理上,JavaScript 的经验其实并不多。然而,每一次版本的更迭,总是会使我们用更先进、更前沿的眼光看待异步编程。它们帮助我们脱离地狱般的原始异步处理机制,化繁为简。因此,一定将有很多足够让我们兴奋的新特性在未来和我们见面。
参考资料
- 《你不知道的 JavaScript(中卷)》,人民邮电出版社,2016
- Promise 对象 - ECMAScript 6 入门
- JavaScript异步处理的那些事儿
- 总结:JavaScript异步、事件循环与消息队列、微任务与宏任务
- 【javascript】异步编年史,从“纯回调”到Promise
- [译] JavaScript:回调是什么鬼?
- Promise - JavaScript | MDN